I have three field in the table say from_city,to_city and distance.
Table name: City_distance
From_city to_city distance
----------------------------------------
A B 100
B A 100
C B 200
C A 300
E F 700
F E 700
Here I want to display the anyone between first and second record because both r round trip and same path and equal distance. Similary for last two records. And I want to display all others only one time. The output should like this
From_city to_city distance
----------------------------------------
A B 100
C B 200
C A 300
E F 700
or
From_city to_city distance
----------------------------------------
B A 100
C B 200
C A 300
F E 700
Thanks for your valuable answer
Sigh....
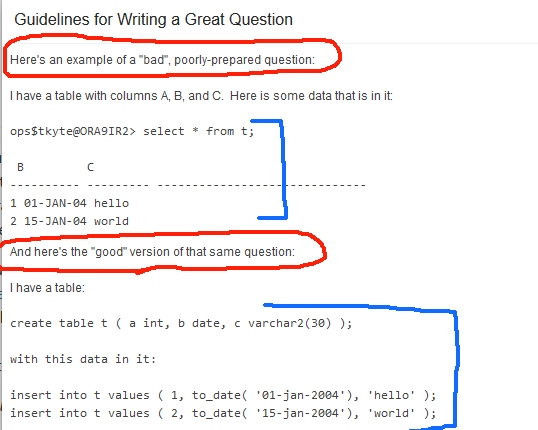
Anyway....
SQL> create table t ( c1 varchar2(2), c2 varchar2(2), d int);
Table created.
SQL> insert into t values ('A','B', 100);
1 row created.
SQL> insert into t values ('B','A', 100);
1 row created.
SQL> insert into t values ('C','B', 200);
1 row created.
SQL> insert into t values ('C','A', 300);
1 row created.
SQL> insert into t values ('E','F', 700);
1 row created.
SQL> insert into t values ('F','E', 700);
1 row created.
SQL> select
2 distinct
3 greatest(c1,c2),
4 least(c1,c2),
5 d
6 from t;
GR LE D
-- -- ----------
F E 700
C A 300
C B 200
B A 100
4 rows selected.