Get Your Information in Order
Part 1 in a series on the basics of the relational database and SQL
By Melanie CaffreySeptember/October 2011
Ask most seasoned professionals working with Oracle Database instances today what their chief complaint regarding performance issues is, and 9 times out of 10, they will answer with responses along the lines of “lack of SQL expertise,” “poorly written SQL statements,” or “poorly trained database programmers.” As relational databases have become a necessary part of everyday business life, knowledge of structured query language (SQL) has become paramount. Paradoxically, however, learning good SQL programming techniques has taken a backseat to creating, for example, user-friendly, attractive interfaces written in database-agnostic programming languages such as Java. Programmers may spend a great deal of time learning their chosen or assigned interface language and very little to no time learning SQL.
This series of SQL 101 articles is for those new to or not yet completely familiar with relational database concepts and SQL coding constructs. It is for anyone learning SQL, tasked with teaching SQL to others within a workgroup, or managing programmers who write database access code. This first article in the series begins with information about the basic building blocks that all programmers (or DBAs/designers/managers) should know when writing their first set of SQL statements.
How Is Data Organized in a Relational Database?Being able to visualize how data is organized in a database is key to retrieving that data quickly and easily. Whenever you withdraw money from an ATM, you are reading and manipulating data. Whenever you purchase anything online, you are changing data. Whether you are banking, shopping, or performing one of many business activities, you are likely interacting with a relational database.
A relational database stores data in a two-dimensional matrix known as a table, and tables generally consist of multiple columns and rows. (I say generally here because it is possible to have a table with just one column and no rows, although it is not common. I will cover that exception in later articles in this series.) Relational databases employ relational database management system (RDBMS) software to help manage the task of giving a user the ability to read and manipulate data without knowing the exact file and/or drive storage device location where a particular piece of information can be found. (Oracle Database is, among other things, an RDBMS.) Users need only know which tables contain the information they seek. The RDBMS relies on SQL constructs and keywords, provided by users, to access the tables and the data contained within the tables’ columns and rows.
How Is Data Represented in a Relational Database?Each table in a relational database usually contains information about a single type of data and has a unique name, distinct from all other tables in that schema. A schema is typically a grouping of objects (such as tables) that serve a similar business function. For example, three tables that contain data about employees, departments, and payroll details, respectively, may exist together inside a schema named HR. There can be only one table named EMPLOYEE inside the HR schema (for the purposes of this introductory explanation, discussions regarding features that support the coexistence of tables with the same name, such as Oracle Database 11g’s editions and Edition-Based Redefinition, are beyond the scope of this article). Now suppose the information in an EMPLOYEE table includes the structure and content shown in Figure 1.
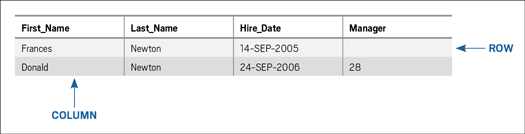
Figure 1: The EMPLOYEE table
A table consists of at least one column, and a column is a set of values of a particular type of data. Like a table’s name within a schema, a column’s name is unique within a table and should clearly identify the type of data it contains. For example, the EMPLOYEE table has columns for the employee’s first name (FIRST_NAME), last name (LAST_NAME), hire date (HIRE_DATE), and manager (MANAGER) in this initial, scaled-down representation. In Figure 1, the employee LAST_NAME Newton represents a single data element within the table. And the HIRE_DATE 14-SEP-2005 represents another single data element.
Further, each row in a table represents a single set of data. For example, the row of the EMPLOYEE table with the FIRST_NAME Frances and LAST_NAME Newton represents a unique set of data. Each intersection of a column and a row represents a value. However, note that some values are not present. In Figure 1, not every row/column combination for MANAGER contains a value. In this case, such values are said to be NULL. A null value is not a blank, a space, or a zero. It is the absence of a value.
The Key to Good RelationsFor a row to be able to uniquely represent a particular set of data, it must be unique for the entire set of row/column value intersections within the table. If the company using the EMPLOYEE table were to hire another employee named Frances Newton on September 14, 2005, and Frances Newton had no MANAGER value associated with her row in the EMPLOYEE table yet, the original entry for Frances Newton would no longer be unique. This coincidence of identical data is referred to as a duplicate. Duplicate entries should not be allowed in tables (more in subsequent articles on why this is so). Therefore, the EMPLOYEE table requires a column that will ensure uniqueness for every row, even if the company hires several employees with the same names and employment details.
Enter the primary key. The primary key is a column that ensures uniqueness for every row in a table. When a primary key is added to the EMPLOYEE table, the two Frances Newtons are no longer alike, because one now has an EMPLOYEE_ID value of 37 and the other has an EMPLOYEE_ID value of 73. Figure 2 illustrates the addition of the EMPLOYEE_ID primary key to the EMPLOYEE table.
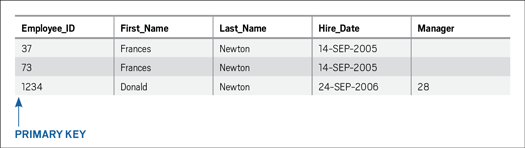
Figure 2: The EMPLOYEE_ID primary key
Note that the EMPLOYEE_ID value appears to have nothing specifically to do with the rest of the column/row combination values that follow it within each row. In other words, it has nothing to do with the employee data per se. This type of key is often a system-generated sequential number, and because it has nothing to do with the rest of the data elements in the table, it is referred to as a synthetic or surrogate key. Using such a key is advantageous in maintaining the uniqueness of each row, because the key is not subject to updates and is therefore immutable. It is best to avoid primary key values that are subject to changes, because they result in complexity that is almost impossible to manage.
A table can have only one primary key, comprising one or several columns. A key comprising more than one column is referred to as a composite or concatenated key. In some cases, a primary key may not be necessary or even appropriate. In most cases, however, it is strongly recommended that every table have a primary key. (Oracle Database does not require every table to have a primary key, however.)
Careful Consideration of Foreign RelationsUp to now, this discussion has focused on how data is organized in a single table. But a relational database also connects (relates) tables and organizes information across multiple tables.
An important connector in a relational database is the foreign key, which identifies a column or set of columns in one table that refers to a column or set of columns in another table. In addition to connecting information, the use of foreign key relations between tables helps keep information organized.
For example, if you store the department name of each employee alongside each employee’s details in the EMPLOYEE table, you may very well see the same department name repeated across multiple employee listings. And any change to a department name would require that name to subsequently be updated in every row for every employee in that department.
If, however, you split the data into two tables, EMPLOYEE and DEPARTMENT, as shown in Figure 3, you will be simultaneously establishing a relationship between the tables by using a foreign key and organizing the data to minimize updates and provide the best-possible data consistency. Consider the resultant data split shown in Figure 3.
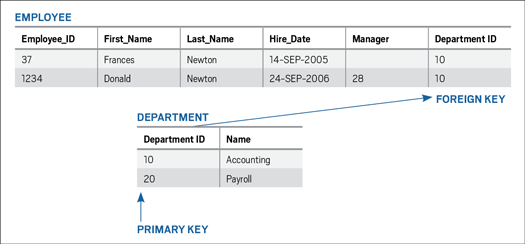
Figure 3: EMPLOYEE and DEPARTMENT tables with a foreign key relationship
In Figure 3, DEPARTMENT_ID is a foreign key column in the EMPLOYEE table—it links the EMPLOYEE and DEPARTMENT tables together. You can find all employee details for every employee in a particular department by looking at that DEPARTMENT_ID column in the EMPLOYEE table. The DEPARTMENT_ID value corresponds to one row in the DEPARTMENT table that provides department-specific information.
Less Is More, or Less Is the NormKey to understanding relational databases is knowledge of data normalization and table relationships. The objective of normalization is to eliminate redundancy and thereby avoid future problems with data manipulation. The rules that govern how a database designer should go about minimizing the duplication of data have been formulated into various normal forms. The design of tables, columns, and primary and foreign keys follows these normalization rules, and the process is called normalization.
There are many normalization rules. The most commonly accepted are the five normal forms and the Boyce-Codd normal form. In my experience, many programmers, analysts, and designers do not normalize beyond the third normal form, although experienced database designers may.
First and foremost. For a table to be in first normal form, all repeating groups must be moved to a new table. Consider the example in Figure 4, in which several office location columns have been added to the EMPLOYEE table.
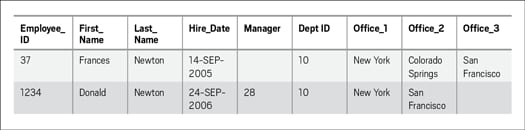
Figure 4: EMPLOYEE table with office location columns—first normal form violation
The table has multiple columns containing office location values for those employees who travel frequently for work and are required to physically work in multiple office locations. Office location values are listed in three columns: OFFICE_1, OFFICE_2, and OFFICE_3. What will happen when one of these employees is required to work in an additional location?
To avoid problems or having to add yet another column, OFFICE_4, the database designer moves the office location data to a separate table named EMPLOYEE_OFFICE_LOCATION, as shown in Figure 5.
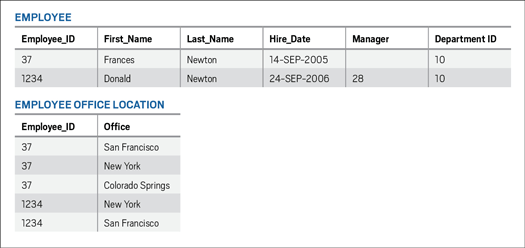
Figure 5: The EMPLOYEE and EMPLOYEE_OFFICE_LOCATION tables in first normal form
Second normal form and composite keys. Second normal form is a special-case normal form that has to do with tables that have composite primary keys. A composite primary key includes two or more columns.
In second normal form, all nonkey columns must depend on the entire primary key. In other words, any nonkey columns added to a table with a composite primary key cannot be dependent on only part of the primary key.
Figure 6 illustrates the EMPLOYEE_OFFICE_LOCATION table, and in this table the primary key is a combination of the EMPLOYEE_ID and OFFICE columns, so any columns added to this table must be dependent on both primary key columns. The OFFICE_PHONE_NUMBER column is dependent solely on the OFFICE column, however; it has nothing to do with the EMPLOYEE_ID column.

Figure 6: Second normal form violation
The EMPLOYEE_OFFICE_LOCATION table in Figure 6 is in violation of second normal form. For this table to comply with second normal form, another table must be created and the OFFICE_PHONE_NUMBER data must be moved to the new table.
The key and nothing but the key. Third normal form expands on second normal form. It dictates that every nonkey column must be a detail or a fact about the primary key. Figure 7 illustrates a third normal form violation.
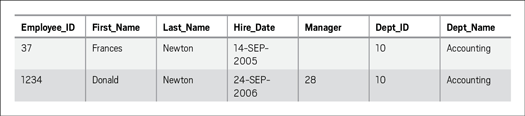
Figure 7: Third normal form violation
The addition of the DEPT_NAME column in this EMPLOYEE table violates third normal form in that DEPT_NAME is dependent on the DEPT_ID value, not the EMPLOYEE_ID value. Complying with the rules of third normal form necessitates creating another table and moving the department name values into this new table, with a foreign key reference from the EMPLOYEE table to the new table. (The solution in Figure 3 demonstrates third normal form: DEPARTMENT_ID is a foreign key column in the EMPLOYEE table.)Where Does SQL Fit In?
With SQL you create new data, delete old data, modify existing data, and retrieve data from a relational database. The following statement, for example, creates a new EMPLOYEE table:
CREATE TABLE employee
(employee_id NUMBER,
first_name VARCHAR2(30),
last_name VARCHAR2(30),
hire_date DATE,
salary NUMBER(9,2),
manager NUMBER);
Note that this statement creates a table with the names of each column (aka data attribute) and each column’s respective datatype and length. For example, this line of the CREATE TABLE statement:
employee_id NUMBER
creates a table column (data attribute) called EMPLOYEE_ID with a datatype of NUMBER. This EMPLOYEE_ID column is therefore defined to contain only numeric data.
The SQL SELECT statement enables you to retrieve, or query, data. For example, the following SQL statement retrieves all FIRST_NAME, LAST_NAME, and HIRE_DATE column values from this article’s EMPLOYEE table:
SELECT first_name, last_name, hire_date FROM employee;
As you can see, the syntax is fairly straightforward.
ConclusionThis article introduced the organization and structure of a relational database. It described tables, columns, and rows and presented examples of data and how it is represented in a relational database. The next article in this SQL 101 series will continue the discussion of data normalization and introduce the SQL execution environment.
Next StepsREAD more about relational database design and concepts
![]() Oracle Database Concepts 11g Release 2 (11.2)
Oracle Database Concepts 11g Release 2 (11.2)
![]() Oracle Database SQL Language Reference 11g Release 1 (11.1)
Oracle Database SQL Language Reference 11g Release 1 (11.1)
![]() READ more SQL 101
READ more SQL 101
DISCLAIMER: We've captured these popular historical magazine articles for your reference. Links etc contained within these article possibly won't work. These articles are provided as-is with no guarantee that the information within them is the best advice for current versions of the Oracle Database.