Sir,
I want to know when I would you a NClob and can not use a Clob ? The character of the database is now US7ASCII. I test using some Chinese and Japanese characters. Looks like I can get back what I inserted on the Clob column, but for NClob column I see some question marks.
SQL> create table test(a clob, b nclob);
SQL> insert into test values (to_clob('你あ'), to_nclob('你あ'));
SQL> col a for a10
SQL> col b for a10
SQL> select * from test;
A B
---------- ----------
你あ ??????
SQL> select parameter, value from v$nls_parameters where parameter like '%CHARACTERSET%';
PARAMETER VALUE
--------------------------- --------------------
NLS_CHARACTERSET US7ASCII
NLS_NCHAR_CHARACTERSET UTF8
Also using JDBC, why the length method of both Clob and NClob seems to return the bytes not the number of characters ? I don't get what I inserted as well. (See some unreadable characters).
public static void main(String[] args) {
try {
Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1522/pdb1", "restdev", "restdev");
Statement stmt = conn.createStatement();
stmt.execute("insert into test values (to_clob('你あ'), to_nclob('你あ'))");
ResultSet rs = stmt.executeQuery("select * from test");
rs.next();
Clob c = rs.getClob(1);
NClob nc = rs.getNClob(2);
System.out.println(c.length());
System.out.println(nc.length());
System.out.println(c.getSubString(1, 10));
System.out.println(nc.getSubString(1, 10));
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
The output is:
6
6
¦ᄑᅠ ̄チツ
������
Thanks,
Xiaohe
You need to be very careful when dealing with "lossy" character sets, ie, ones that cannot hold all the information you need. Just because we store the data does not mean it will be correctly represented later.
For example, consider the following 8bit characters (stored in my database which is WE8MSWIN1252, ie, an 8bit charset).
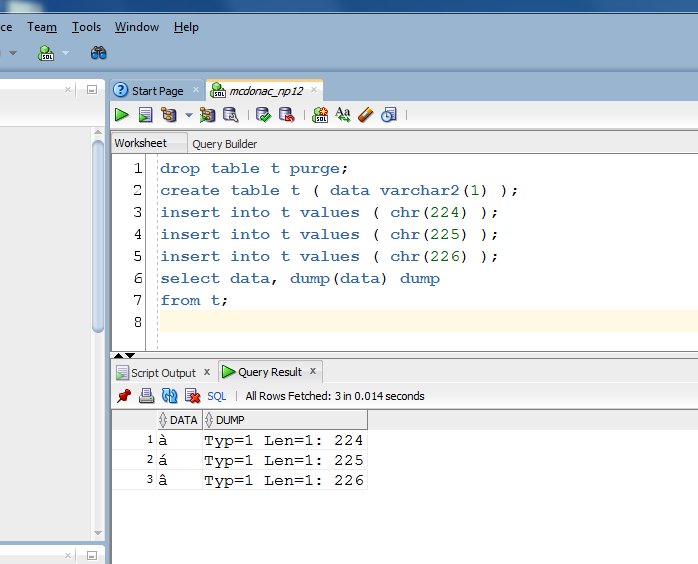
If I select them back to a client with NLS set to US7ASCII, then I'll get 'a' for all three results, ie, I'll lose all the accents etc. Similarly, if I stored them in a US7ASCII database, they would still probably be stored fine, and possibly even displayed fine, but that is "good luck" more than anything else - we're relying on some bits to align. If you need to style multibytes characters, then you want the entire database to be a multibyte charset (like UTF8) or you would use the N-datatype columns (nvarchar2,nclob).
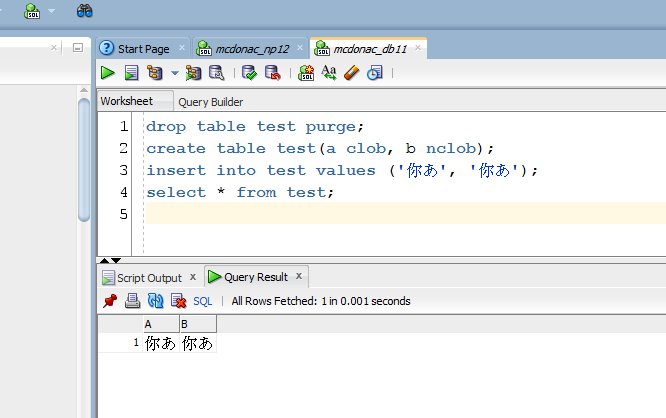
The example you gave for example, is fine in both cases for a *multibyte* database (eg this is my UTF8 database)
For Java, check out MOS note 2190241.1. It's got a series of examples on specifying/inserting/updating characters for nclob.